- Published on
Tìm hiểu chi tiết và so sánh các thuật toán optimizer
- Authors
- Name
- SnowyField
- @SnowyField1906


Các thuật toán Optimizer (Tối ưu) là một phần quan trọng lĩnh vực Machine Learning. Chúng giúp cho việc tìm kiếm cực trị của Loss Function (Hàm Mất mát) nhanh và hiệu quả hơn. Điều này sẽ giúp tăng tốc quá trình train model nhưng vẫn đảm bảo độ chính xác cao.
Để hiểu rõ hơn về các thuật toán optimizer, chúng ta sẽ cùng tìm hiểu về các thuật toán optimizer thông dụng nhất và so sánh hiệu quả của chúng trong bài viết này. Bao gồm: Gradient Descent, SGD, Momentum, NAG, Adagrad, RMSProp/Adadelta và Adam.

Khuyến nghị đọc trước Toàn tập về bài toán Least Squares và các phương pháp giải để sẵn sàng trước khi đi vào bài viết này.
Khái niệm
Thuật toán Optimizer (Tối ưu) về cơ bản là một thuật toán dùng để tìm ra các giá trị tối ưu nhất bằng cách giải bài toán tìm cực tiểu cho Loss Function (Hàm Mất mát) của model. Có thể hiểu nôm na rằng loss function thể hiện mức độ sai lệch giữa giá trị dự đoán và giá trị thực tế, do đó để có một model tối ưu, chúng ta cần tìm ra các giá trị sao cho loss function đạt giá trị nhỏ nhất có thể.
Thông thường việc giải bài toán tìm kiếm cực trị của một hàm số là một bài toán rất khó, vì vậy các thuật toán optimizer thường sẽ có một thuật toán chung là thực hiện các vòng lặp cho đến khi tìm ra được bộ giá trị thỏa mãn.
Nhắc lại
Loss Function
Loss Function (Hàm Mất mát) hay còn gọi là Error Function (Hàm Lỗi) là một hàm số dùng để đánh giá mức độ sai lệch giữa giá trị dự đoán và giá trị thực tế. Các giá trị cần optimize thường là các Weight/Parameter (Tham số) của model.
Có rất nhiều loại loss fuction với từng bài toán khác nhau như Regression (Hồi quy), Classification (Phân loại), Clustering (Phân cụm),... Tuy nhiên, hầu hết chúng sẽ có cùng một cách tính là lấy tổng của các giá trị sai lệch trên toàn bộ tập dữ liệu. Trong đó, với mỗi điểm dữ liệu , thường sẽ được tính dựa trên giá trị dự đoán và giá trị thực tế :
Learning Rate
Learning Rate (Tốc độ Học) là một hệ số được sử dụng trong các thuật toán optimizer, nó thể hiện mức độ ảnh hưởng của từng parameter đến giá trị loss function. Learning rate càng lớn thì mức độ ảnh hưởng càng lớn, và ngược lại.
Tùy theo mục đích của model mà ta có thể tăng/giảm learning rate. Learning rate càng cao sẽ giúp model học nhanh hơn và tiết kiệm thời gian, nhưng cũng sẽ gây ra sự thay đổi giữa các parameter càng lớn, dẫn đến việc training không ổn định, dao động mạnh và có thể không hội tụ được.
Chi tiết về Gradient Descent
Cho loss function với các tham số:
Để tiện trong việc giải thích, ta sẽ giả sử với là số lượng điểm dữ liệu.
Ta có thể tính được gradient của theo . Đây chính là một vector đạo hàm riêng của theo , vector này thể hiện hướng tăng nhanh nhất của tại :
Cho là learning rate, con số này này thể hiện mức độ ảnh hưởng của từng parameter đến giá trị . Do đó ta sẽ dùng nó để tích với vector để có được vector với độ dài gấp lần so với ban đầu, giúp cho việc di chuyển nhanh hơn:
Khi đó, để tìm được điểm cực trị của , ta chỉ cần đi theo hướng ngược lại của với hệ số cho đến khi đạt được điều kiện dừng. Bằng cách lấy điểm hiện tại trừ đi độ biến thiên , ta sẽ có được điểm mới :
Lặp lại quá trình trên cho đến khi đạt được điều kiện dừng, ta sẽ có được giá trị tối ưu.
Thuật toán Gradient Descent
Các bước thực hiện:
- Tìm
- Tính gradient của tại : .
- Tìm : .
- Cập nhật lại các parameter : .
- Lặp từ các bước 2-4 trên cho đến khi đạt được điều kiện dừng.
Công thức tổng quát:
Kết luận về Gradient Descent
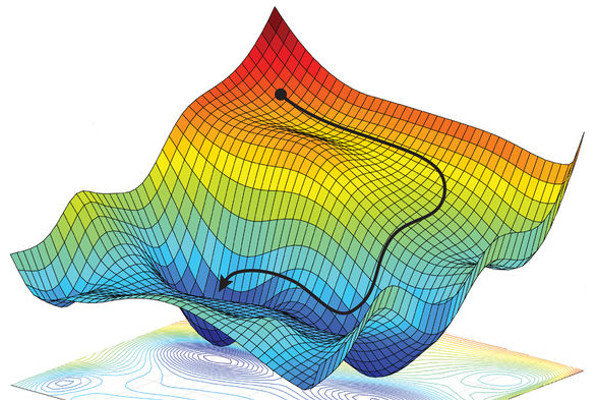
Ta có thể thấy đường đi của Gradient Descent trông như một quả bóng lăn xuống sườn núi. Điều này cũng chính là ý nghĩa của gradient trong lĩnh vực Vector Calculus (Giải tích Vector).
Ưu điểm của Gradient Descent
- Đơn giản và dễ hiểu.
- Dễ cài đặt.
Nhược điểm của Gradient Descent
- Phụ thuộc vào learning rate .
- Phụ thuộc vào parameter số khởi tạo ban đầu.
- Thường rơi vào các local minima (cực tiểu địa phương) thay vì global minima (cực tiểu toàn cục).
- Không thể thoát ra khỏi saddle point (điểm yên ngựa).
- Chậm khi số lượng data training vào lớn.
Các thuật toán optimizer
SGD
Trong Gradient Descent, parameter số sẽ được cập nhật toàn bộ sau mỗi lần tính toán gradient. Điều này sẽ khiến cho việc tính toán trở nên rất chậm, đặc biệt là khi số parameter số rất lớn.
Trong khi đó, mấu chốt của thuật toán này là tìm ra được hướng tăng nhanh nhất của tại , do đó ta không cần hướng này phải chính xác hoàn toàn mà có thể lấy xấp xỉ để giảm thiểu thời gian tính toán.
Như đã biết, là tổng của các giá trị sai lệch trên toàn bộ tập dữ liệu, với mỗi là sai lệch của 1 điểm dữ liệu. Do đó, để tính gradient của , ta phải đạo hàm tổng của các theo từng parameter . Tuy nhiên, ta có thể xấp xỉ gradient bằng cách chỉ tính trên 1 của 1 điểm dữ liệu ngẫu nhiên.
Và đây chính là cách hoạt động của biến thể Stochastic Gradient Descent (SGD). Điều này tuy sẽ tăng số lần cập parameter số (số vòng lặp) lên rất nhiều, nhưng mỗi lần lặp cũng sẽ nhanh hơn rất nhiều so với Gradient Descent.
Thuật toán SGD
Các bước thực hiện:
- Tìm dựa trên một điểm dữ liệu ngẫu nhiên đã chọn:
- Tính gradient của tại :
- Tìm : .
- Cập nhật lại các parameter : .
- Lặp lại các bước 1-4 trên cho đến khi đạt được điều kiện dừng.
Công thức tổng quát:
Kết luận về SGD
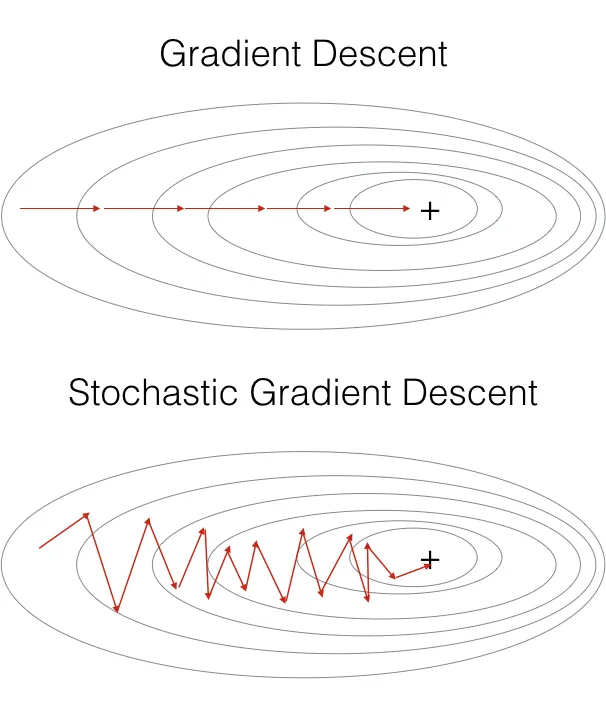
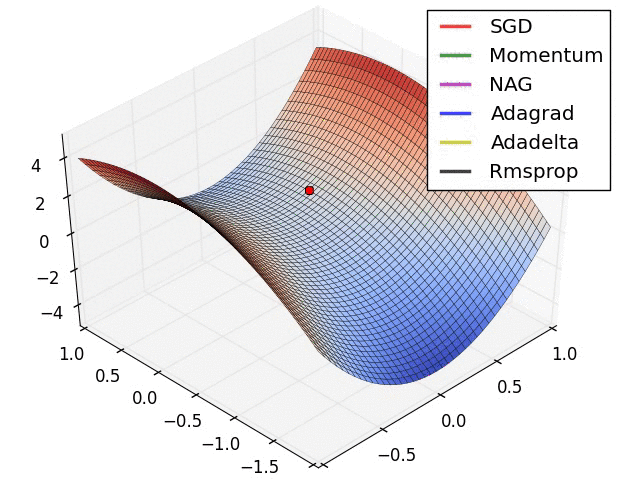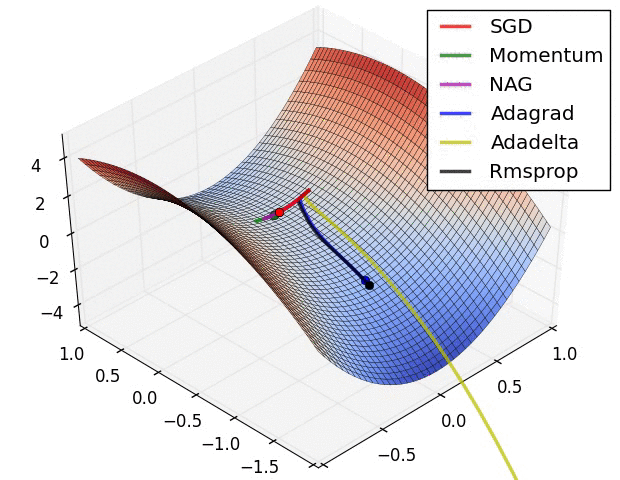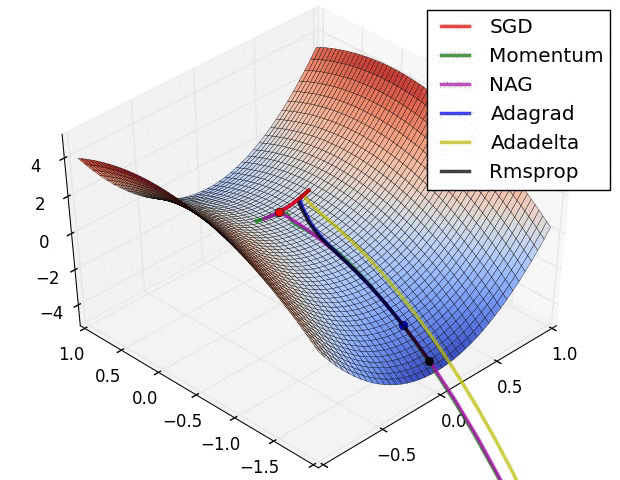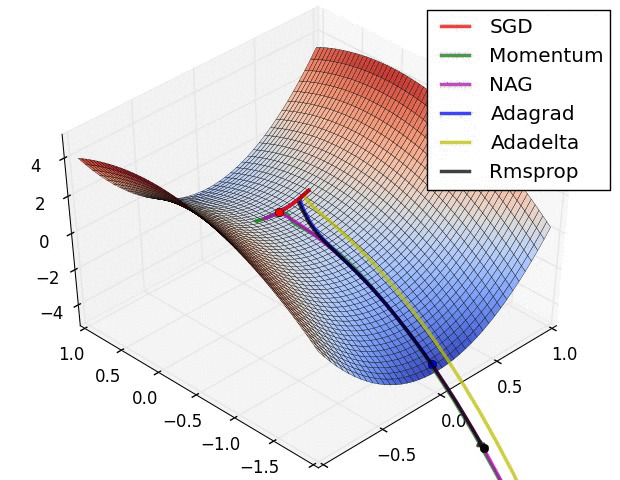
Ta có thể thấy đường đi của SGD là đường zigzag. Lí do là vì mỗi lần lặp, nó chỉ tính gradient dựa trên một điểm dữ liệu ngẫu nhiên, mà điểm này không thể đại diện cho toàn bộ tập dữ liệu. Do đó, nó sẽ cho ra một hướng đi không chính xác, và cần nhiều lần lặp hơn để đạt được điều kiện dừng.
Ví dụ, ta có một lớp học với 100 học sinh, thay vì tính điểm trung bình bằng cách lấy toàn bộ điểm của 100 học sinh, ta chỉ lấy 1 học sinh ngẫu nhiên và dùng nó để đại diện cho toàn bộ lớp học. Ban đầu, số điểm này có thể là , nhưng sau đó sẽ tăng lên hoặc giảm đi tùy vào điểm của học sinh được chọn tiếp theo. Việc tăng giảm liên tục này gây ra sự dao động của điểm số, khiến nó đi theo đường zigzag.
Ưu điểm của SGD
- Nhanh hơn so với Gradient Descent.
Nhược điểm của SGD
- Phụ thuộc vào learning rate .
- Phụ thuộc vào parameter số khởi tạo ban đầu.
- Thường rơi vào các local minima thay vì global minima.
- Không thể thoát ra khỏi saddle point.
Mini-Batch GD
Là một thuật toán hoàn toàn giống với SGD, chỉ khác là thay vì tính trên điểm dữ liệu duy nhất, ta sẽ tính trên điểm dữ liệu ngẫu nhiên (lớn hơn nhưng vẫn nhỏ hơn tổng số điểm dữ liệu rất nhiều).
Chúng ta sẽ không cần phải đi vào chi tiết thuật toán này.
Momentum
Momentum (Quán tính) hay Stochastic Gradient Descent with Momentum là một biến thể của SGD, phương pháp này sinh ra nhằm giải quyết vấn đề dao động mạnh trong quá trình tìm kiếm cực trị của SGD. Phương pháp này cũng giải quyết được việc không thể thoát ra khỏi local minima hay saddle point.
Ý tưởng của phương pháp này là giả lập một lực quán tính, làm giảm tốc độ khi đổi hướng theo một hệ số . Điều này giúp cho việc di chuyển nhanh hơn và giảm thiểu sự dao động của đường đi. Do đó các đường zigzag sẽ hẹp hơn và tiến về phía cực trị nhanh hơn, ngoài ra lực quán tính này cũng có khả năng vượt qua được các local minima hay thoát ra khỏi saddle point.
Thuật toán này được triển khai bằng cách thay vì trừ trực tiếp gradient hiện tại vào , ta sẽ trừ với tổng của 2 vector là vector trước đó và gradient hiện tại:
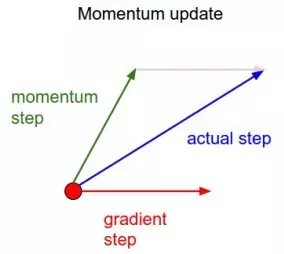
Qua hình ảnh ta có thể hình dung được hướng đi của Momentum là tổng của 2 vector: hướng đi trước đó và gradient hiện tại.
Lúc này, vector mới vừa có thông tin của gradient hiện tại vừa giữ lại được một phần của vector trước đó tùy thuộc vào hệ số .
Thuật toán Momentum
Các bước thực hiện:
- Tìm dựa trên một điểm dữ liệu ngẫu nhiên đã chọn:
- Tính gradient của tại :
- Tìm : .
- Cập nhật lại vận tốc :
- Cập nhật lại các parameter : .
- Lặp lại các bước 1-5 trên cho đến khi đạt được điều kiện dừng.
Công thức tổng quát:
Kết luận về Momentum
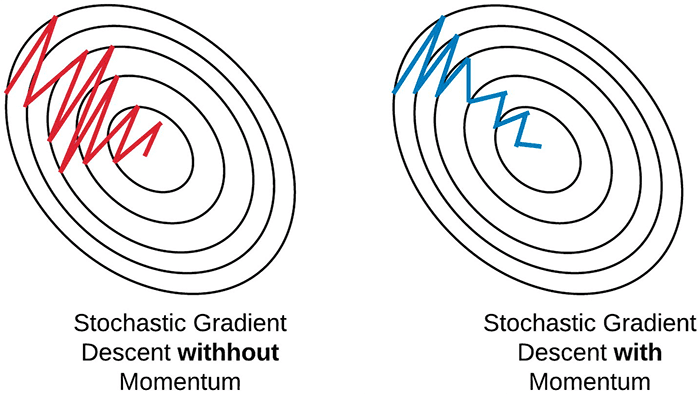
Ta có thể thấy rằng đường đi của Momentum đã hẹp hơn so với SGD và tiến về phía cực trị nhanh hơn. Chúng ta sẽ biết được Momentum có thể vượt qua được local minima như thế nào trong hình minh họa ở phần tiếp theo.
Ưu điểm của Momentum
- Nhanh hơn so với SGD.
- Giảm thiểu sự dao động của đường đi.
- Có thể thoát ra khỏi local minima hay saddle point.
Nhược điểm của Momentum
- Khi đến đích, vì quán tính nên vẫn còn mất nhiều thời gian dao động tại chỗ trước khi có thể dừng lại.
- Phụ thuộc vào learning rate .
NAG
Nesterov Accelerated Gradient (NAG) là một biến thể của Momentum, phương pháp này sinh ra nhằm giải quyết vấn đề mất thời gian dao động khi đến đích của Momentum.
Ý tưởng của phương pháp này là dự đoán trước vị trí tiếp theo của dựa trên vector quán tính và hệ số trước đó.
Sau đó, ta sẽ tính gradient của tại vị trí dự đoán này và dùng nó để cập nhật lại các parameter .
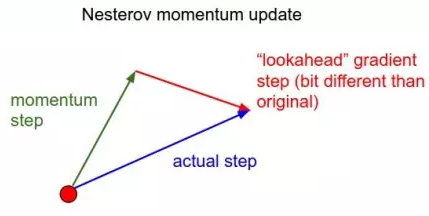
Qua hình ảnh ta có thể hình dung được hướng đi của NAG là tổng của 2 vector: hướng đi trước đó và gradient tại vị trí dự đoán.
Thuật toán NAG
Các bước thực hiện:
- Tìm dựa trên một điểm dữ liệu ngẫu nhiên đã chọn:
- Dự đoán vị trí tiếp theo của :
- Tính gradient của tại :
- Tìm : .
- Cập nhật lại vận tốc :
- Cập nhật lại các parameter : .
- Lặp lại các bước 1-6 trên cho đến khi đạt được điều kiện dừng.
Công thức tổng quát:
Kết luận về NAG
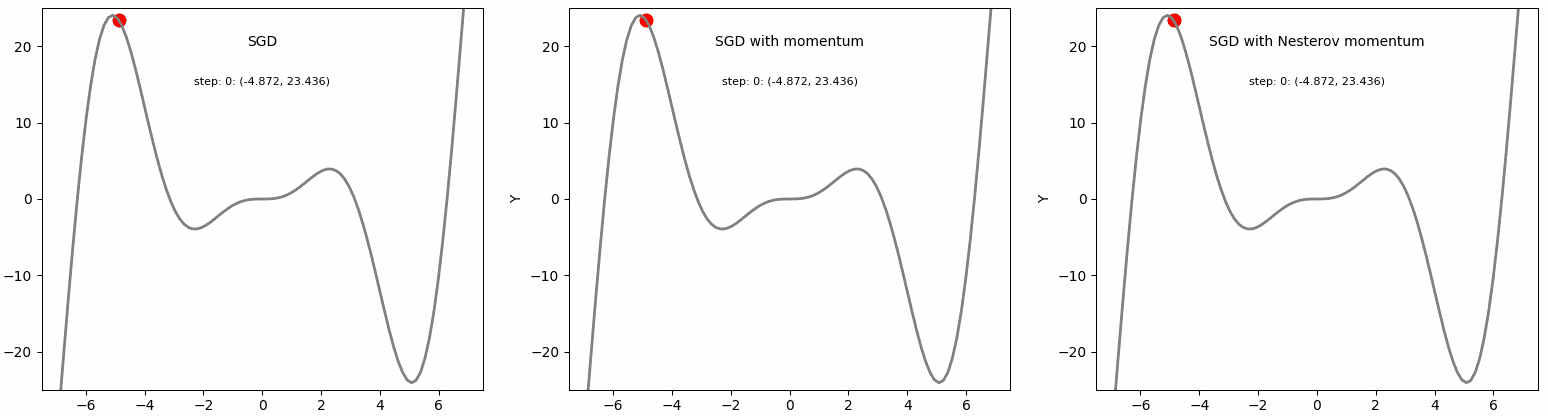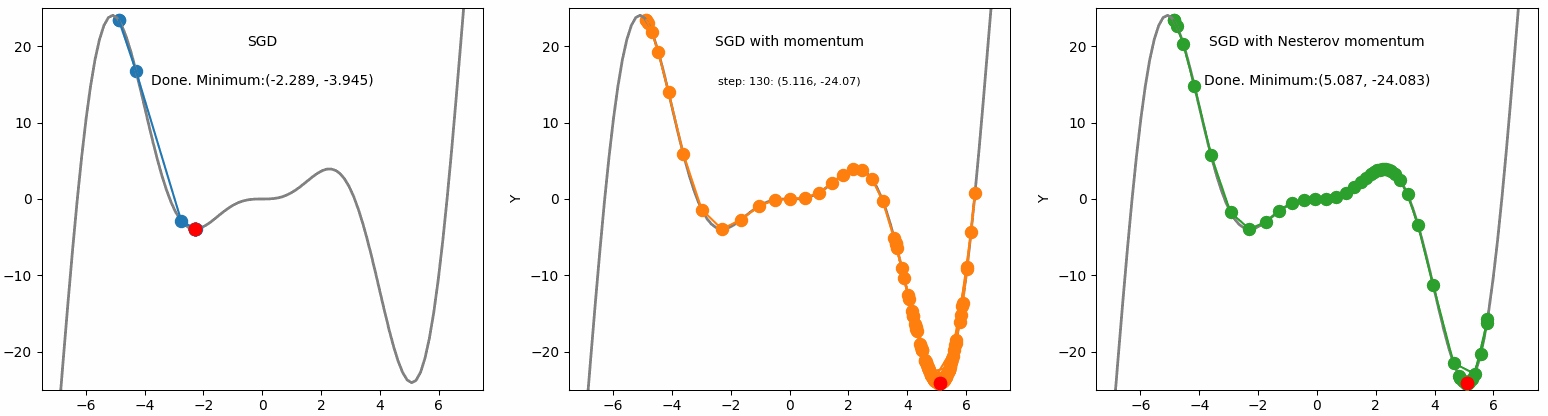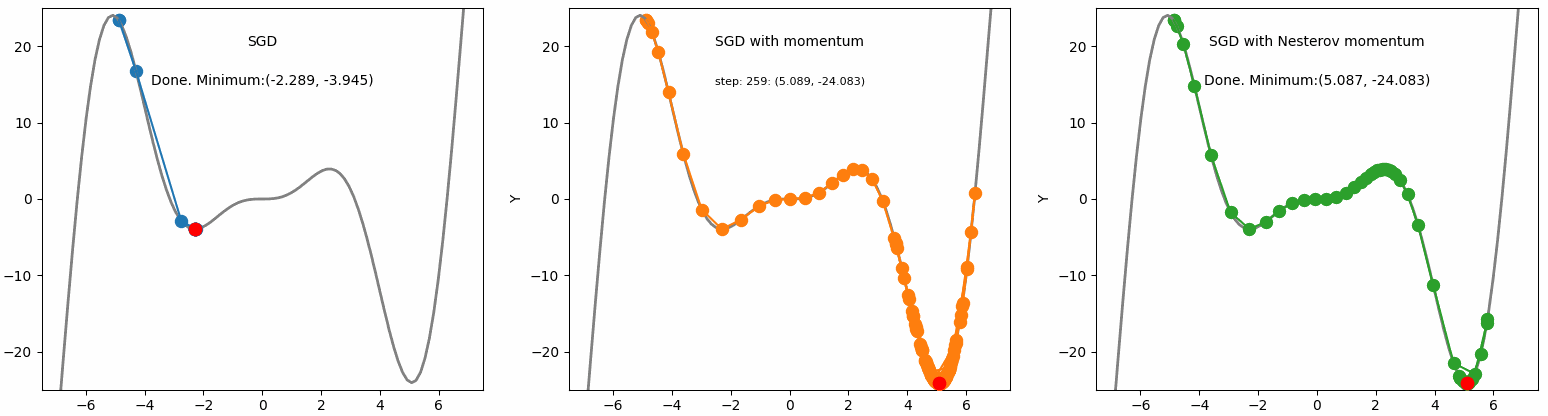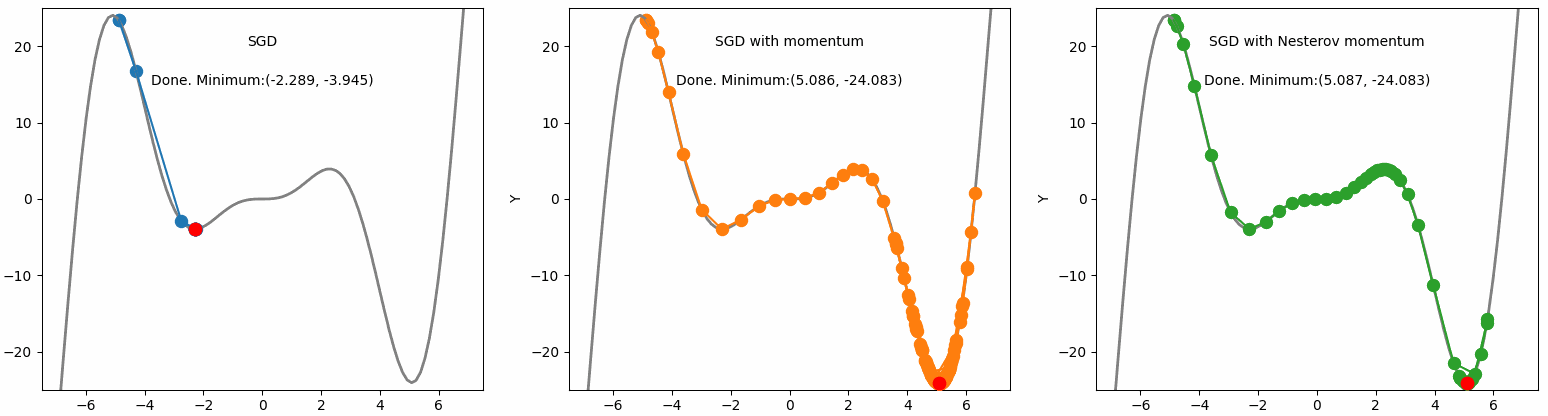
Ta có thể thấy rằng cả Momentum và NAG đều có khả năng vượt qua được local minima. Tuy nhiên, NAG không bị mất thời gian dao động khi đến đích như Momentum.
Ưu điểm của NAG
- Nhanh hơn so với Momentum.
- Giảm thiểu sự dao động của đường đi.
- Có thể thoát ra khỏi local minima hay saddle point.
- Không bị mất thời gian dao động khi đến đích.
Nhược điểm của NAG
- Phụ thuộc vào learning rate .
Adagrad
Adaptive Gradient (Adagrad) là một biến thể của SGD, phương pháp này sẽ sử dụng một learning rate biến thiên theo thời gian. Điều này giúp cho việc di chuyển nhanh hơn và giảm thiểu sự dao động của đường đi khi gần đến cực trị.
Ta cho là tổng bình phương của các gradient đã tính trước đó, là một hệ số rất nhỏ được thêm vào để tránh trường hợp chia cho . Ta sẽ cập nhật lại theo công thức:
Với việc chia cho , ta sẽ có được một learning rate nhỏ hơn so với ban đầu. Điều này giúp cho việc di chuyển nhanh hơn và giảm thiểu sự dao động của đường đi khi gần đến cực trị.
Nhờ đó, ta có thể cài đặt learning rate ban đầu thật cao để giúp cho việc di chuyển nhanh hơn rất nhiều so với SGD mà không cần lo việc không thể hội tụ về sau.
Thuật toán Adagrad
Các bước thực hiện:
- Tìm dựa trên một điểm dữ liệu ngẫu nhiên đã chọn:
- Tính gradient của tại :
- Tính :
- Tính learning rate :
- Tìm : .
- Cập nhật lại các parameter : .
- Lặp lại các bước 1-5 trên cho đến khi đạt được điều kiện dừng.
Công thức tổng quát:
Ưu điểm của Adagrad
- Nhanh hơn nhiều so với SGD.
- Giảm thiểu sự dao động của đường đi.
- Có thể tránh được saddle point.
Nhược điểm của Adagrad
- Phụ thuộc vào parameter số khởi tạo ban đầu.
- Thường rơi vào các local minima thay vì global minima.
- Tổng bình phương của các gradient có thể trở nên quá lớn khiến cho learning rate giảm nhanh và dừng lại trước khi đạt được cực trị.
RMSProp/Adadelta
RMSProp/Adadelta là hai biến thể của Adagrad, hai phương pháp này được phát triển đồng thời và độc lập, nhằm giải quyết vấn đề tổng bình phương của các gradient có thể trở nên quá lớn khiến cho learning rate giảm nhanh và dừng lại trước khi đạt được cực trị.
Ý tưởng của hai phương pháp này là thay vì cho là tổng bình phương của toàn bộ các gradient đã tính trước đó, ta sẽ cho là trung bình cộng của chính nó với bình phương của gradient hiện tại. Với ý nghĩa này, sẽ phụ thuộc vào phần lớn gradient trước đó.
Hệ số (thường được chọn là ) thể hiện mức độ quên đi gradient này.
Thuật toán RMSProp/Adadelta
Các bước thực hiện:
- Tìm dựa trên một điểm dữ liệu ngẫu nhiên đã chọn:
- Tính gradient của tại :
- Tính :
- Tính learning rate :
- Tìm : .
- Cập nhật lại các parameter : .
- Lặp lại các bước 1-6 trên cho đến khi đạt được điều kiện dừng.
Công thức tổng quát:
Ưu điểm của RMSProp/Adadelta
- Nhanh hơn so với Adagrad.
- Giảm thiểu sự dao động của đường đi.
- Có thể tránh được saddle point.
- Không xảy ra tình trạng learning rate giảm nhanh và dừng lại trước khi đạt được cực trị.
Nhược điểm của RMSProp/Adadelta
- Phụ thuộc vào parameter số khởi tạo ban đầu.
- Thường rơi vào các local minima thay vì global minima.
Adam
Chúng ta có thể thấy từ SGD sinh ra hai trường phái khác nhau, một cái sử dụng lực quán tính, một cái sử dụng learning rate biến thiên. Và đây chính là ý tưởng của Adam (Adaptive Moment Estimation), phương pháp này thống nhất cả hai ý tưởng trên lại với nhau tạo nên một thuật toán mạnh mẽ. Đây cũng là thuật toán optimizer được sử dụng nhiều nhất hiện nay.
Ngoài dùng để lưu trữ trung bình cộng của bình phương các gradient, Adam định nghĩa thêm dùng để lưu trữ trung bình cộng của các gradient.
Như RSMProp, thường được cho là , còn thường được cho là .
Tuy nhiên vì quá nhỏ, do đó các giá trị này có xu hướng tiến về về sau khi khởi tạo, ta sẽ tính lại:
Thuật toán Adam
Các bước thực hiện:
- Tìm dựa trên một điểm dữ liệu ngẫu nhiên đã chọn:
- Tính gradient của tại :
- Tính :
- Tính :
- Tính :
- Tính :
- Tính learning rate :
- Tìm : .
- Cập nhật lại các parameter : .
- Lặp lại các bước 1-8 trên cho đến khi đạt được điều kiện dừng.
Công thức tổng quát:
Ưu điểm của Adam
- Nhanh hơn so với RMSProp/Adadelta.
- Giảm thiểu sự dao động của đường đi.
- Có thể tránh được saddle point.
- Không xảy ra tình trạng learning rate giảm nhanh và dừng lại trước khi đạt được cực trị.
- Có thể thoát ra khỏi local minima.
- Không phụ thuộc vào parameter số khởi tạo ban đầu.
- Không phụ thuộc vào learning rate .
Nhược điểm của Adam
Không có nhược điểm nào đáng kể.
Nadam
Có lẽ chúng ta đã quên NAG với ý tưởng skip một bước bằng cách sử dụng gradient cho vị trí dự doán. Nadam (Nesterov-accelerated Adaptive Moment Estimation) là một biến thể của Adam kết hợp với NAG. Cho ra một thuật toán optimizer hoàn hảo và toàn diện.
Chúng ta sẽ không cần phải đi vào chi tiết thuật toán này.
Kết luận
✿
Khái niệm
◎
Nhắc lại
▣
Loss Function
▣
Learning Rate
✿
Chi tiết về Gradient Descent
◎
Thuật toán Gradient Descent
◎
Kết luận về Gradient Descent
◎
Ưu điểm của Gradient Descent
◎
Nhược điểm của Gradient Descent
✿
Các thuật toán optimizer
◎
SGD
▣
Thuật toán SGD
▣
Kết luận về SGD
▣
Ưu điểm của SGD
▣
Nhược điểm của SGD
◎
Mini-Batch GD
◎
Momentum
▣
Thuật toán Momentum
▣
Kết luận về Momentum
▣
Ưu điểm của Momentum
▣
Nhược điểm của Momentum
◎
NAG
▣
Thuật toán NAG
▣
Kết luận về NAG
▣
Ưu điểm của NAG
▣
Nhược điểm của NAG
◎
Adagrad
▣
Thuật toán Adagrad
▣
Ưu điểm của Adagrad
▣
Nhược điểm của Adagrad
◎
RMSProp/Adadelta
▣
Thuật toán RMSProp/Adadelta
▣
Ưu điểm của RMSProp/Adadelta
▣
Nhược điểm của RMSProp/Adadelta
◎
Adam
▣
Thuật toán Adam
▣
Ưu điểm của Adam
▣
Nhược điểm của Adam
◎
Nadam
✿
Kết luận